
こんにちは!
先日RPAの講師を務めさせて頂いたのですが
想定してない質問が出て色々力技で解決してしまい反省してます。
なかでもちょっと気になったのがテキストの平文ファイルから特定の文字を含む行を取得してその値を取ってくるという課題。
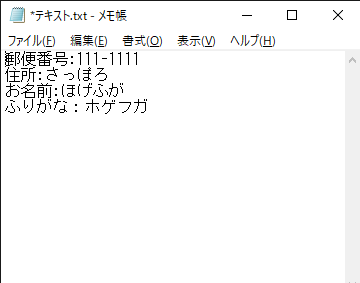
このテキストファイルのお名前「ほげふが」を取得するという処理ですね。
CSVばかりに注目してましたが、たしかにこういう使い方もよく出そうなのでちょっと正統性のあるやり方を調べて見ました。
まずフローはこちら
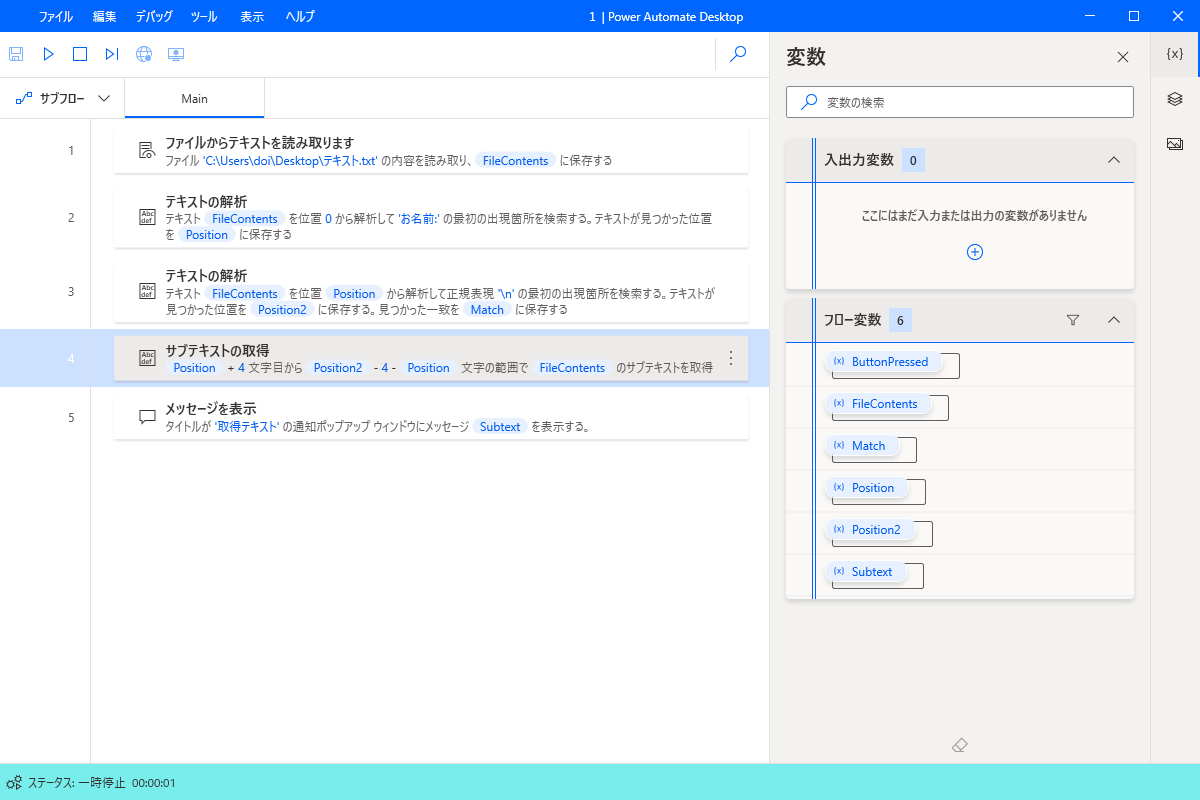
2-4で解析させてます。
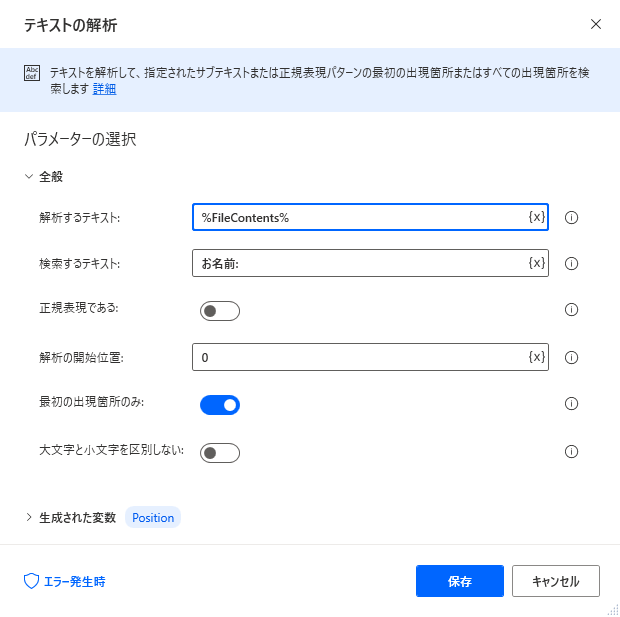
まず工程:2ではお名前の文字の出現位置を調べます
工程:3ではその行の終わり。つまり改行位置までの文字数を調べます。
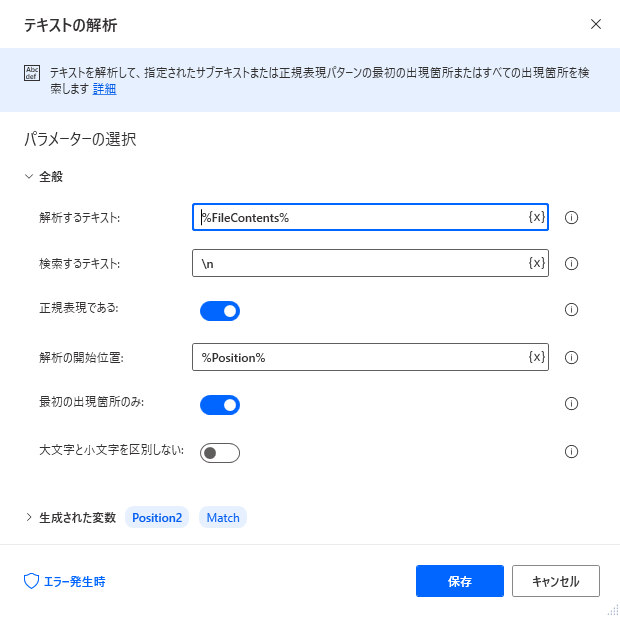
この際、検索の開始位置はお名前を見つけた文字数から始めます。そうでないと一行目の最初でみつけてしまいます。
工程:4で対象文字を取得。
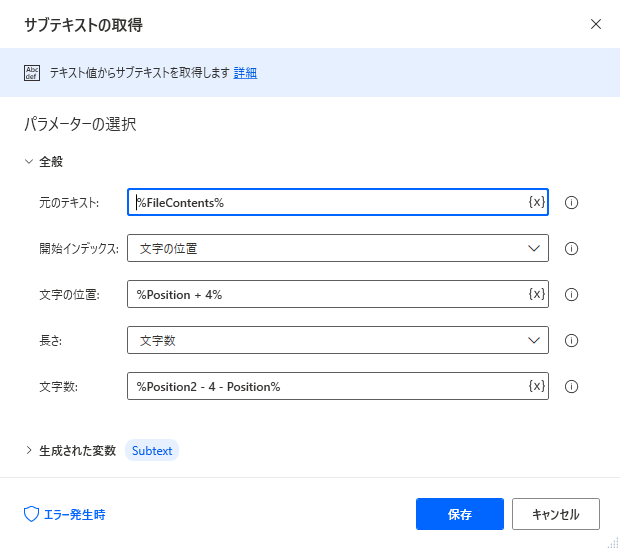
ここで
文開始の文字位置を%Position + 4%
つまり「お名前:」発見時の文字数+「お名前:」自体の文字数4を合わせた所をスタートと定義。
そこから取得する文字数として
%Position2 -4 -Position%
と設定しました。
これは「お名前:」が含まれる行の改行コードまでの文字【Position2】からお名前:の4文字【4】とお名前:発見時の文字数【Position】を引いた値になります。
だいぶややこしいですね…
コレで正常にお名前の値が取得出来ました。
ただね…
正規表現とか改行コードまで持ち出すと普通にエンジニアの領域になってくるので
「プログラムがわからなくてもある程度使える」という触れ込みではpower automate desktop使えないな…とも思いました。
